I've been thinking about possible applications for the network simulation/analysis program that Steve Thompson and I developed as part of my PhD thesis.*
I propose to investigate the effect of response order/timing in respondent-driven sampling on estimates of network parameters.
Here I'm assuming that samples are taken in waves. That is, a collection of seed members of the population are identified and given the initial coupons. If the standard deviation of the response times is small compared to the mean, the network of the population is being sampled in a manner similar to breadth first search (BFS). If the standard deviation of response times is large relative the mean, the network ends up being sampled in a manner closer to that of a depth first search (DFS). Each of these sampling methods has the potential to provide vastly different information about the sample.
Such an investigation would include four parts:
1) Motivating questions: Why would we care about the time it takes members of the population to be entered into the sample? Because perhaps these times could be influenced by different incentive structures. If they can, what is best? If they cannot, we can do a what-if analysis to explore counter-factuals. Does timing matter? What sampling and incentive setups are robust to the effects of response times? Are there statistical methods that can adjust for the effects of response times?
2) Find some real respondent-driven samples, preferably by looking in the literature of PLoS-One and using the data that is included with publications, but possibly by asking other researchers individually.
Look at the time stamp of each observation in each data set, if available, and fit a distribution such as gamma(r, beta) to the time delay between giving a recruitment coupon and that recruitment coupon being used. Compare the parameter estimates that each data set produces to see if there is a significant difference between them and see if there's any obvious reason or pattern behind the changes.
3) Generate a few networked populations and sample from each one many times using the different response-delay time distributions found in Part 2. Are there any significant changes to the network statistics that we can compute from the samples we find? That is, how does the variation of the statistics between resamples under one delay time distribution compare to the variation between delay time distributions?
4) Employ the full ABCN system to get estimates of whatever network parameters we can get for case ij, 1 <= i,j <= M, where M is the number of datasets we find. Case ij would be using the observed sample from the ith dataset, with simulations in the ABCN system using the delay distribution estimated from the jth dataset.
This way, we could compare the variation in the network parameters attributable to the sample that was actually found, and how much was attributable to the difference in time it took for recruitments to be entered into the survey. Also, we effectively will have performed a what-if analysis on the datasets we use - and seeing if the conclusions from the datasets would have been different if the recruited respondents had been responded with different delay structures.
---------------------------------------
*This network simulation/analysis system takes an observed sample of network and
computes a battery of summarizing statistics of the sample. Then it
simulates and samples from many networks and computes the same battery
from each sample. It estimates the parameters of the original sample by
looking at the distribution of parameters from the simulation samples
that were found to be similar to the observed sample.
This
will all be explained again, and in greater detail when I post my
thesis after the defense in... gosh.. a month. Basically it's
statistical inference turned upside down, where you generate the
parameters and see if they make the sample you want, instead of starting
with the sample and estimating a parameter value or distribution. The
base method is called Approximate Bayesian Computation.
Friday 31 July 2015
Sunday 26 July 2015
Prediction Assisted Streaming
The online game path of exile has a trick for reconciling a game that requires quick reaction times with the limitations of servers: it predicts the actions of the players. It doesn't have to predict far ahead - a couple hundred milliseconds - to keep the action running smoothly most of the time.
Prediction on this time frame isn't hard in principle; play often involves performing the same short
action repeatedly, such as firing an arrow, so the default prediction is just more of that. When the server predicts incorrectly, it usually has enough time to 'rewind' to the present and handle things as they come. The prediction is just an extra buffering layer that's in place when there is a lot of server lag.
Does video or music streaming do this? Could it?
In a song with a repetitive baseline, could the information to the client computer include: "repeat the sound from time x with the following deviations included in the buffer", rather than "play the following sound"? The "sound at time x" in this case is a note from the baseline and the deviations being the result of a human playing an instrument and not hitting the note exactly the same every time. In a case like that, potentially less data would need to be sent to reproduce the song, allowing for longer buffers or higher sound quality.
Likewise for video. Consider a live video feed of a soccer match, in which a player is running across the field. Video prediction may determine there is an object moving at some speed in some direction and predict a few frames ahead where that object will be, and thus what pixels to draw in that spot. Then the streaming service, making the same prediction, could just send the video information that deviates from this prediction.
For repetitive patterns like an animation of a like a spinning wheel or sparkling logo of a sports team. If the wheel spins in a predictable fashion, internet bandwidth could be saved by describing the movement of the wheel as "spinning as expected", where matching prediction software on the server and client sides both recognize that that part of the screen is taken up by an object in 10-frame loop.
This is different from encoding only the pixels that change from frame to frame. This prediction would incorporate likely changes in a picture based on simple movement patterns or on repetitive animations.
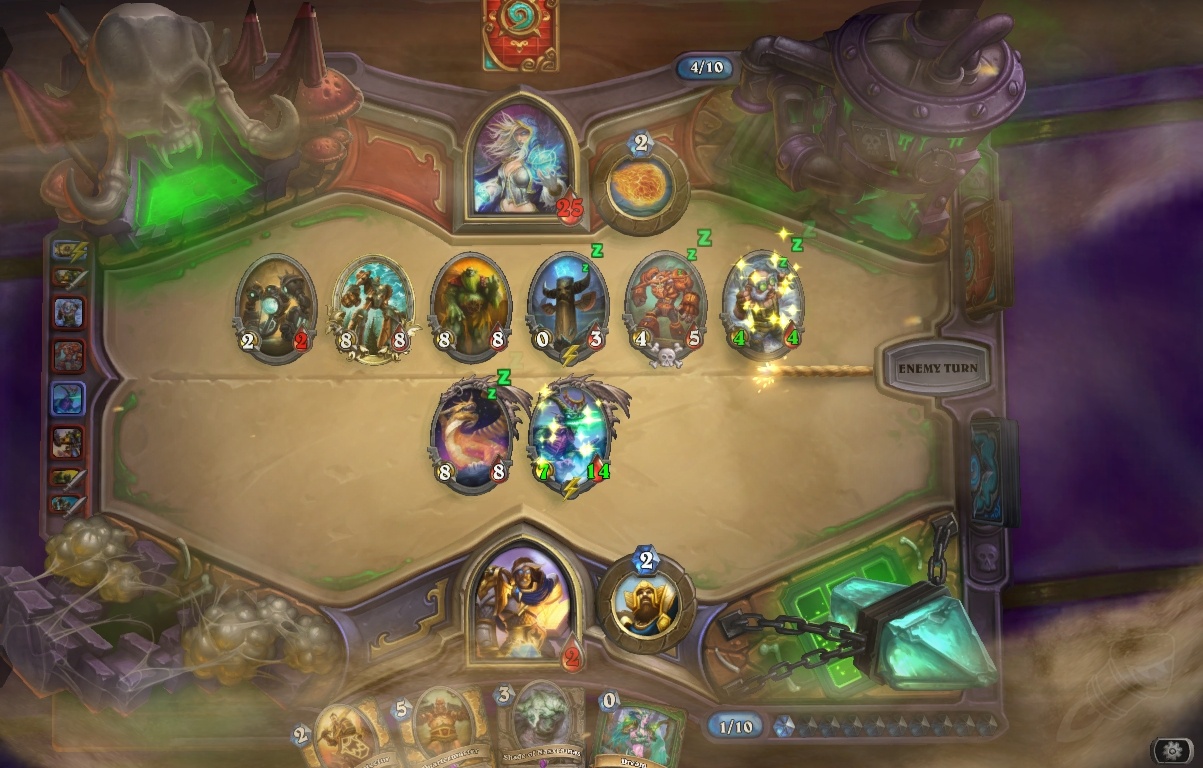
Consider a streaming game of hearthstone, like the last time I pretended to know about video encoding. There are certain animations that regularly impact video quality, such as sand sweeping across the entire screen, that involve a many pixels changing for a non-trivial amount of time. The video encoder does fine when the picture is mostly the same from frame to frame, but introduce one of these effects that causes a lot of pixels change at once, and the quality of the live stream.
{kind=link}
However, the sand effect is one of sand moving slowly across the screen, its movement is predictable in that any one pixel of the effect is likely to follow the same trajectory as it did in the last few frames. Predictive video encoding is more scalable than the application specific encoding I mentioned before, but with time it could achieve the same effect if it was able to recognize frequently used pre-rendered effects such as lightning all over the screen. A predictive video encoder could recognize the first few frames of the 'lightning storm' effect and predict the rest without having to send any information about that part of the screen.
{kind=link}
I'm no expert on video encoding, so this may all be jibberish.
Previous post on video encoding in Twitch, the possibility of application specific codecs.
Sunday 19 July 2015
Using optim() to get 'quick and dirty' solutions, a case study on network graphs
The optim() function in base R, is a generalized optimizer for continuous functions. It looks for the minimum of some objective function that you define across some continuous parameter space that you define.
In this post, I show how to use optim() to find a (inelegant, but workable) solution to do something very complex, plot a network of nodes based on the shortest path between them, with relatively little programming effort.
In this post, I show how to use optim() to find a (inelegant, but workable) solution to do something very complex, plot a network of nodes based on the shortest path between them, with relatively little programming effort.
Saturday 11 July 2015
Danni and Jeremy's Wedding Speech
As requested, here is the speech that was given for Danni-Lynn Laidlaw and Jeremy Strang's wedding last month.
[Party 1] was Danni-Lynn
[Party 2] was Jeremy
[Member of Audience] was Calen, Danni's brother.
Regular text represents my own additions
Italic text is taken verbatim from the Government of British Columbia's standard ceremony,
of which the bold italic parts are immutable and cannot be changed.
Anything in underline is spoken by one of the two parties being married.
The standard ceremony can be found at http://www2.gov.bc.ca/assets/gov/residents/vital-statistics/marriages/vsa718.pdf
-----------------------------------------------
Majestic Ladies, Handsome Gentlemen, and [Member of Audience].
We have assembled here to acknowledge a force that ruthlessly devoured billions before and will no doubt continue to consume live in their prime until the sky crumbles.
This remorseless and unceasing force is called love. These two, though their forms appear before you, are hopelessly lost -- beyond mourning , really.
Today we witness the passing of [Party 1] and [Party 2] into the penultumate stage of their falling to this force. The true word for this stage makes all who hear it cry blood and vomit leeches. Thankfully I lack the four tongues required to pronounce it. However, even the English word has terrified lesser men before. That word is "marriage".
The state of matrimony, as understood by us, is a state ennobled and enriched by a long and honourable tradition of devotion, set in the basis of the law of the land, assuring each participant an equality before the law, and supporting the common right of each party to the marriage.
There is assumed to be a desire for life-long companionship, and a generous sharing of the help and comfort that a couple ought to have from each other, through whatever circimstances of sickness or health, joy or sorrow, proserity or adversity, the lives of these parties may experience.
Marriage is therefore not to be entered upon thoughtlessly or irresponsibly, but with a due and serious understanding and appreciation of the ends for which it is undertaken, and of the material, intellectual, and emotional factors which will govern its fullfillment.
It is by its nature a state of giving rather than taking, of offering rather than receiving, for marriage requires the giving of one's self to support the marriage and the marriage and the home in which it may flourish.
It is into this high and serious state that these two persons desire to unite.
Therefore:
I charge and require of you both in the presence of these witnesses, that if either of you know of any legal impediment to this marriage, you do now reveal the same.
Let [Party 1] repeat after me:
"I solemnly declare that I do not know of any lawful impediment why I, [Person 1] may not be joined in matrimony to [Person 2]."
Let [Party 2] repeat after me:
"I solemnly declare that I do not know of any lawful impediment why I, [Person 2] may not be joined in matrimony to [Person 1]."
There having been no reason given why this couple may not be married, nor any reasonless jibbering that could be interpreted as such, I ask you to give answer to these questions.
Do you [Party 1] undertake to afford to [Party 2] the love of your person, the comfort of your companionship,m and the patience of your understanding, to respect the dignity of their person, their own inalienable personal rights, and to recognize the right of counsel and the consultation upon all matters relating to the present, future, and alternate realities of the household established by this marriage?
(A prompt of 'do you, or do you not' may help here)
[Party 1]: I do.
Do you [Party 2] undertake to afford to [Party 1] the love of your person, the comfort of your companionship,m and the patience of your understanding, to respect the dignity of their person, their own inalienable personal rights, and to recognize the right of counsel and the consultation upon all matters relating to the present, future, and alternate realities of the household established by this marriage?
(Again, a prompt of 'do you, or do you not' may help here. Especially because doing it twice makes it sound planned)
[Party 2]: I do.
Let the couple join their right hands, claws, tentacles, feelers, probosci, or pseudopods, and let [Party 1] repeat after me.
I call on those present to witness that I, [Party 1], take [Party 2] to be my lawful wedded (wife/husband/spouse), to have and hold, from this day forward, in madness and in health, in whatever circumstances life may hold for us.
and let [Party 1] repeat after me.
I call on those present to witness that I, [Party 1], take [Party 2] to be my lawful wedded (wife/husband/spouse), to have and hold, from this day forward, in madness and in health, in whatever circumstances life may hold for us.
Inasmuch as you have made this declaration of your vows concerning one another, and have set these rings before me, I ask that now these rings be used and regarded as a seal and a confirmation and acceptance of the vows you have made.
Let [Party 1] place the ring on the third noodly appendage of [Party 2]'s left hand, repeat after me:
With this ring, as the token and pledge of the vow and covenant of my word, I call upon those persons present, and those unpersons lurking among us beyond mortal sight, that I, [Party 1], do take thee [Party 2], to be my lawful wedded (wife/husband/spouse)
Let [Party 2] say after me:
In receiving this ring, being the token and pledge of the covenant of your word, I call upon those persons present to witness that I [Party 2] do take thee [Party 1] to be my lawful wedded (wife/husband/spouse).
Let [Party 2] place the ring on the third noodly appendage of [Party 1]'s left hand, repeat after me:
With this ring, as the token and pledge of the vow and covenant of my word, I call upon those persons present, and those unpersons lurking among us beyond mortal sight, that I, [Party 2], do take thee [Party 1], to be my lawful wedded (wife/husband/spouse)
Let [Party 1] say after me:
In receiving this ring, being the token and pledge of the covenant of your word, I call upon those persons present to witness that I [Party 1] do take thee [Party 2] to be my lawful wedded (wife/husband/spouse).
And now, forasmuch as you [Party 1] and [Party 2] have consented to legal wedlock, and have declared your solemn intention in this company, before these witnesses, and in my presence, and have exchanged these rings as the pledge of your vows to each other, now upon the authority vested in me by the province of British Columbia, I pronounce you as duly married.
You may kiss.
[Party 1] was Danni-Lynn
[Party 2] was Jeremy
[Member of Audience] was Calen, Danni's brother.
Regular text represents my own additions
Italic text is taken verbatim from the Government of British Columbia's standard ceremony,
of which the bold italic parts are immutable and cannot be changed.
Anything in underline is spoken by one of the two parties being married.
The standard ceremony can be found at http://www2.gov.bc.ca/assets/gov/residents/vital-statistics/marriages/vsa718.pdf
-----------------------------------------------
Majestic Ladies, Handsome Gentlemen, and [Member of Audience].
We have assembled here to acknowledge a force that ruthlessly devoured billions before and will no doubt continue to consume live in their prime until the sky crumbles.
This remorseless and unceasing force is called love. These two, though their forms appear before you, are hopelessly lost -- beyond mourning , really.
Today we witness the passing of [Party 1] and [Party 2] into the penultumate stage of their falling to this force. The true word for this stage makes all who hear it cry blood and vomit leeches. Thankfully I lack the four tongues required to pronounce it. However, even the English word has terrified lesser men before. That word is "marriage".
The state of matrimony, as understood by us, is a state ennobled and enriched by a long and honourable tradition of devotion, set in the basis of the law of the land, assuring each participant an equality before the law, and supporting the common right of each party to the marriage.
There is assumed to be a desire for life-long companionship, and a generous sharing of the help and comfort that a couple ought to have from each other, through whatever circimstances of sickness or health, joy or sorrow, proserity or adversity, the lives of these parties may experience.
Marriage is therefore not to be entered upon thoughtlessly or irresponsibly, but with a due and serious understanding and appreciation of the ends for which it is undertaken, and of the material, intellectual, and emotional factors which will govern its fullfillment.
It is by its nature a state of giving rather than taking, of offering rather than receiving, for marriage requires the giving of one's self to support the marriage and the marriage and the home in which it may flourish.
It is into this high and serious state that these two persons desire to unite.
Therefore:
I charge and require of you both in the presence of these witnesses, that if either of you know of any legal impediment to this marriage, you do now reveal the same.
Let [Party 1] repeat after me:
"I solemnly declare that I do not know of any lawful impediment why I, [Person 1] may not be joined in matrimony to [Person 2]."
Let [Party 2] repeat after me:
"I solemnly declare that I do not know of any lawful impediment why I, [Person 2] may not be joined in matrimony to [Person 1]."
There having been no reason given why this couple may not be married, nor any reasonless jibbering that could be interpreted as such, I ask you to give answer to these questions.
Do you [Party 1] undertake to afford to [Party 2] the love of your person, the comfort of your companionship,m and the patience of your understanding, to respect the dignity of their person, their own inalienable personal rights, and to recognize the right of counsel and the consultation upon all matters relating to the present, future, and alternate realities of the household established by this marriage?
(A prompt of 'do you, or do you not' may help here)
[Party 1]: I do.
Do you [Party 2] undertake to afford to [Party 1] the love of your person, the comfort of your companionship,m and the patience of your understanding, to respect the dignity of their person, their own inalienable personal rights, and to recognize the right of counsel and the consultation upon all matters relating to the present, future, and alternate realities of the household established by this marriage?
(Again, a prompt of 'do you, or do you not' may help here. Especially because doing it twice makes it sound planned)
[Party 2]: I do.
Let the couple join their right hands, claws, tentacles, feelers, probosci, or pseudopods, and let [Party 1] repeat after me.
I call on those present to witness that I, [Party 1], take [Party 2] to be my lawful wedded (wife/husband/spouse), to have and hold, from this day forward, in madness and in health, in whatever circumstances life may hold for us.
and let [Party 1] repeat after me.
I call on those present to witness that I, [Party 1], take [Party 2] to be my lawful wedded (wife/husband/spouse), to have and hold, from this day forward, in madness and in health, in whatever circumstances life may hold for us.
Inasmuch as you have made this declaration of your vows concerning one another, and have set these rings before me, I ask that now these rings be used and regarded as a seal and a confirmation and acceptance of the vows you have made.
Let [Party 1] place the ring on the third noodly appendage of [Party 2]'s left hand, repeat after me:
With this ring, as the token and pledge of the vow and covenant of my word, I call upon those persons present, and those unpersons lurking among us beyond mortal sight, that I, [Party 1], do take thee [Party 2], to be my lawful wedded (wife/husband/spouse)
Let [Party 2] say after me:
In receiving this ring, being the token and pledge of the covenant of your word, I call upon those persons present to witness that I [Party 2] do take thee [Party 1] to be my lawful wedded (wife/husband/spouse).
Let [Party 2] place the ring on the third noodly appendage of [Party 1]'s left hand, repeat after me:
With this ring, as the token and pledge of the vow and covenant of my word, I call upon those persons present, and those unpersons lurking among us beyond mortal sight, that I, [Party 2], do take thee [Party 1], to be my lawful wedded (wife/husband/spouse)
Let [Party 1] say after me:
In receiving this ring, being the token and pledge of the covenant of your word, I call upon those persons present to witness that I [Party 1] do take thee [Party 2] to be my lawful wedded (wife/husband/spouse).
And now, forasmuch as you [Party 1] and [Party 2] have consented to legal wedlock, and have declared your solemn intention in this company, before these witnesses, and in my presence, and have exchanged these rings as the pledge of your vows to each other, now upon the authority vested in me by the province of British Columbia, I pronounce you as duly married.
You may kiss.
Subscribe to:
Posts (Atom)